
Ктг расшифровка 10 баллов: КТГ при беременности в Москве: сделать кардиотокографию плода (КТГ)
КТГ плода при беременности, расшифровка кардиотокограммы в баллах по шкале Фишер, нормы для недель.
Кардиотокография плода (КТГ) — диагностический метод, позволяющий зарегистрировать и проанализировать изменения сердечной деятельности развивающегося внутриутробно плода.
Сердечная деятельность малыша зависит от влияния симпатической и парасимпатической систем организма. Эти системы начинают регулировать сердечную деятельность малыша в третьем триместре беременности. Поэтому, кардиотокографическое исследование имеет диагностическую ценность с 28 недель беременности. Оптимально в амбулаторных условиях — с 33-34 недель.
Кардиотокограф, его ещё называют фетальный монитор, имеет 3 датчика:
1-й ультразвуковой, накладывается на переднюю брюшную стенку беременной в проекции спинки малыша. Он регистрирует сердечную деятельность плода (кардиограмма).
2-й тензометрический, накладывают на дно матки в область водителя ритма. Он регистрирует эпизоды сокращения матки (токограмма). В третьем триместр они могут возникать спорадически. Во время родов- носят регулярный характер.
Он регистрирует эпизоды сокращения матки (токограмма). В третьем триместр они могут возникать спорадически. Во время родов- носят регулярный характер.
3-й датчик помещают в руку беременной. Будущая мама самостоятельно регистрирует эпизоды шевеления плода, нажимая на кнопку.
Информация от этих датчиков поступает в кардиотокографический прибор, обрабатывается, преобразуется в графические кривые, отражающиеся на мониторе в виде кардиограммы, токограммы и регистрации шевелений плода. Фетальный монитор самостоятельно оценивает результаты кардиотокограммы в баллах по шкале Фишер. Но только лечащий врач может дать правильную интерпретацию результатов КТГ.
Для того, чтобы получить правильные результаты КТГ нужно придерживаться некоторых правил:
- Исследование проводиться после 33-34 нед. беременности,
- Перед исследованием будущая мама может полакомиться чем нибудь сладким, чтобы обеспечить хорошую двигательную активность малыша.
- Исследование длится не менее 15 мин, и до 60 мин.
- Исследование проводиться в положении мамы на спине, на боку или сидя, в таком положении, при котором малыш наиболее активно, но не чрезмерно шевелится.
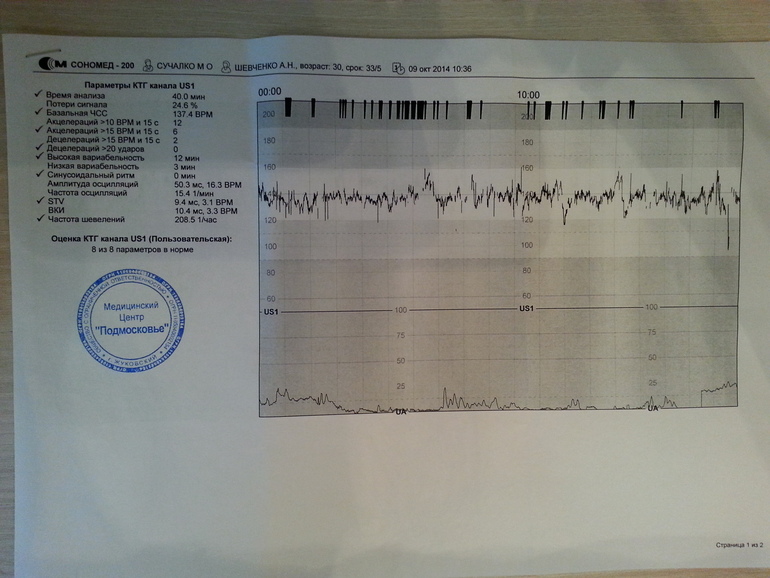
Показатели кардиотокограммы
Базальный ритм— это средняя арифметическая сердечного ритма плода, отраженная на кардиотокограмме
Вариабельность— это показатель, который отражает кратковременные изменения сердечной деятельности от базального ритма
Акцелерации — это ускорение ритма более чем на 15 ударов в минуту, которое длится по времени более 10 секунд.
Децелерации— замедление ритма более 15 ударов в минуту, продолжительностью более 10 секунд.
Для удобства показатели кардиотокограммы сведены в одну таблицу и оцениваются в баллах (есть множество вариантов авторских таблиц и соответственно балльного диапозона). Некоторые фетальные мониторы могут оценивать показатели кардиотокограммы как индекс ПСН (показатель состояния плода) соответственно программному обеспечению.
| 2 балла | 1 балл | 0 баллов | |
|---|---|---|---|
| Базальный (основной) ритм | От 120 до 160 | От 100 до 180 | Менее 100, более 180 |
| Амплитуда | От 6 до 25 | 3-5 | < 3 |
| Вариабельность | > 6 | 3-6 | < 3 |
| Количество эпизодов акцелераций за 40 мин | >5 | 1-4 | отсутствуют |
| Децелерации | Не регистрируются | Кратковременные | Длительные, тяжелые |
Расшифровка результатов оценивается в баллах:
- КТГ считается хорошей, если набрала 8-10 баллов;
- 4-7 свидетельствует о признаках гипоксии, в таких ситуациях требуются ежедневный контроль и лечение.
- Менее 4 баллов крайне неблагоприятно.

Патологическая КТГ и/или низкий балл КТГ могут быть при:
- Тугом обвитии пуповиной плода
- Наличии патологии пуповины (истинный или ложный узел пуповины)
- Гипоксии плода
- Пороках сердца плода
- Нарушении ритма сердца у матери (пороки сердца, изменение функции щитовидной железы, прием лекарственных средств, влияющих на ритм сердца)
- Гемолитическая болезнь плода (резус или групповой конфликт)
- Хориоамнионит
- и другое.
При получении сомнительных результатов КТГ, можно провести дополнительные методы исследования:
- УЗИ плода, допплерографию сосудов маточно-плацентарного и фето-плацентарного кровотока,
- КТГ в динамике или
- устранить влияние лекарственных препаратов
- провести медикаментозную коррекцию патологических состояний мамы и плода.
Всё это можно проводить в тех случаях, когда состояние плода по данным КТГ не является критичным.
При неудовлетворительном результате КТГ может потребоваться интенсивная терапия и даже срочное родоразрешение.
Таким образом, кардиотокографическое исследование имеет большое значение в работе акушера-гинеколога и влияет на тактику ведения беременной.
КТГ плода можно пройти в медицинском центре «Экстра». Цена на процедуру минимальна и доступна большей части пациентов. Исследование не доставляет дискомфорта ни женщине, ни малышу и совершенно безопасна. При беременности с осложнениями исследование проводится каждую неделю, пока не наступит нормализация состояния плода.
цена 2 800 р. на кардиотокографию при беременности
Помимо различных исследований и анализов во второй половине беременности женщины проходят кардиотокографию. Это достаточно информативное и чувствительное диагностическое мероприятие. Однако далеко не все знают, для чего оно проводится, как расшифровываются результаты, как проводится исследование и с какой недели делают КТГ.
Что показывает КТГ?
Каждая женщина в положении должна знать, что показывает КТГ и как проводится данное исследование. Кардиотокография представляет собой один из эффективных способов оценки состояния будущего малыша, при котором используется специальное приспособление – кардиотокограф, а проводится анализ акушером-гинекологом. Специалист перед началом проведения диагностического мероприятия объясняет будущей маме, что такое КГТ и что показывает данный анализ.
В основе кардиотокографии лежит физический эффект Доппера, который напоминает традиционную ультразвуковую диагностику. Его принцип заключается в том, что специальное устройство производит ультразвук, волны отражаются от пульсирующего сердца ребенка, изменяя свою частоту, и возвращаются на сканирующий датчик. Расшифровка результатов КТГ позволяет определить частоту сердцебиения ребенка в состоянии покоя и во время движения, при этом учитывается влияние различных факторов, включая особенности сокращения матки.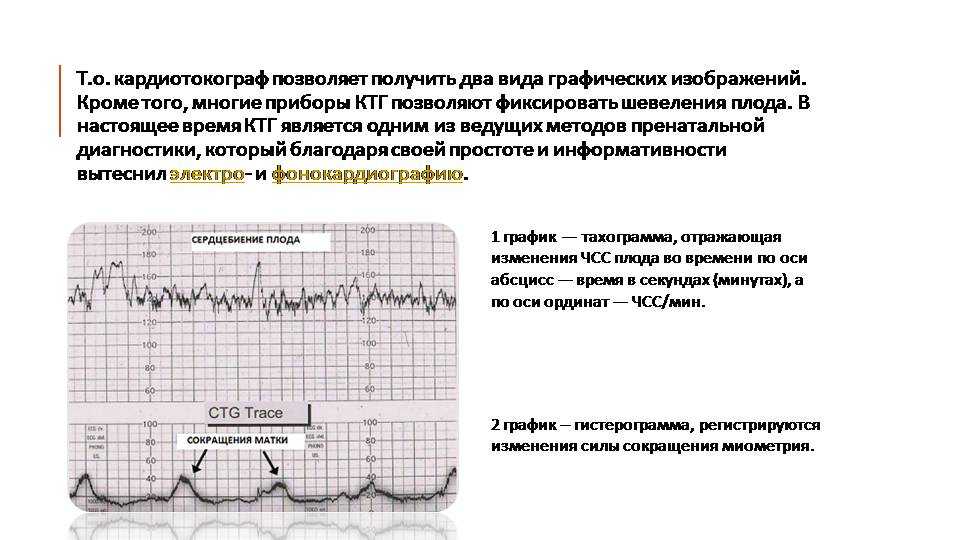
Исходя из того, как расшифровывается КТГ, удается провести диагностику для опровержения таких серьезных заболеваний:
- инфекционное поражение;
- гипоксия;
- сердечно-сосудистые патологии;
- много- либо маловодие;
- риск преждевременных родов.
Если после КТГ расшифровка показателей указывает на какие-либо проблемы, то это дает возможность лечащему врачу провести дополнительную диагностику и своевременно перейти к лечению.
Расшифровка показателей КТГ
Состояние плода и ход течения беременности доктор определяет по нескольким параметрам, которые удается узнать в процессе проведения кардиотокографии. К ним относятся:
- базальный ритм. Данный параметр определяет число ударов сердца плода в периоды схваток. При схватках на КТГ нормальное число сердцебиений составляет 120-160 за 60 секунд.
- частота ударов сердца.
- вариабельность базального ритма.
 Показатель указывает на высоту перемен в частоте сердцебиений, в среднем он варьируется в диапазоне от 5 до 25 сокращений.
Показатель указывает на высоту перемен в частоте сердцебиений, в среднем он варьируется в диапазоне от 5 до 25 сокращений. - акцелерации. Непродолжительное ускорение биения сердца, измеряется за временной промежуток, например, за 15 сек. Замер акцелерации позволяет зафиксировать неожиданное увеличение сокращений сердца. Это нормальное явление, которое происходит несколько раз на протяжении 10 минут и является ответной реакцией на активность малыша.
- децелерации. Снижение количества сердцебиений на протяжении 15 сек. В идеальном случае децелерации не должно быть вообще, хотя на практике такое состояние бывает, но оно должно быть кратковременным. Если наблюдается продолжительное уменьшение числа сокращений, то есть все предпосылки для проведения более серьезной диагностики.
При расшифровке анализов лечащий врач учитывает все эти критерии. После чего полученные значения сравнивает с нормой КТГ.
Как расшифровать КТГ?
При проведении КТГ по фишеру, расшифровка происходит с использованием системы выставления баллов.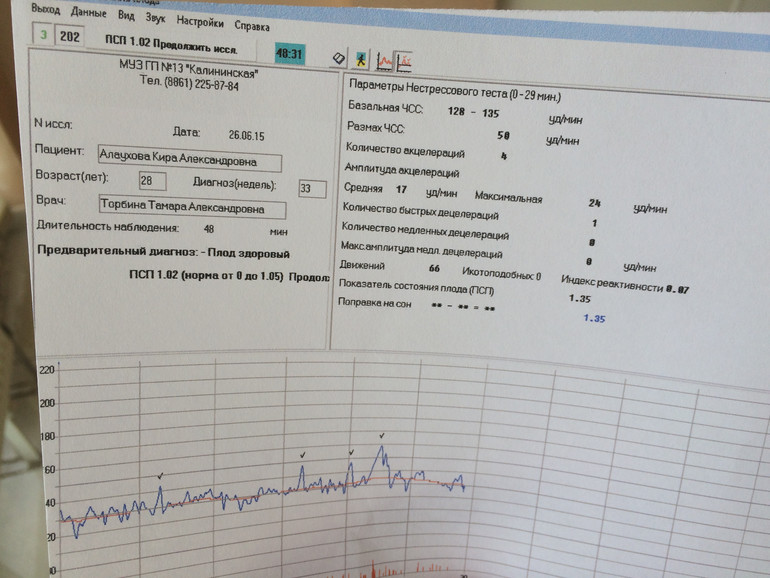 Здесь учитываются все критерии. Оценки исходя из базального ритма выставляются так:
Здесь учитываются все критерии. Оценки исходя из базального ритма выставляются так:
- 0 – частота сердечных сокращений меньше 100 либо свыше 180;
- 1 – результат в пределах от 100 до 120 сокращений либо от 160 до 180;
- 2 – диапазон сокращений 120-160 ударов.
При диагностике вариабельности выставляют применяют такое оценивание:
- 0 – высота меньше 3 ударов;
- 1 – высота составляет от 3 до 6 ударов;
- 2 – результат свыше 6 ударов.
После замера акселерации специалист выставляет:
- 0 – отсутствие подъемов сердечных сокращений;
- 1 – подъемы происходят, независимо от активности малыша;
- 2 – увеличение сердечной частоты происходит только при движении плода.
Анализ децелерации выполняется аналогично:
- 0 – несвоевременное и продолжительное сокращение числа сердцебиений;
- 1 – позднее и кратковременное;
- 2 – полностью отсутствуют признаки патологичного состояния.
Помимо вышеперечисленных параметров специалист оценивает амплитуду графика сердечных колебаний за одну минуту. Для этого используются такие критерии:
- 0 – 5 колебаний;
- 1 – от 5 до 9 либо свыше 25 ударов;
- 2 – колебания в пределах от 10 до 25.
После измерения всех показателей происходит подсчет полученных значений. Затем можно судить о состоянии плода и течении беременности:
- 8-10 баллов расшифровка КТГ в этом случае свидетельствует о нормальном развитии ребенка;
- 5-7 – говорят о первых симптомах гипоксии. Как правило, такой результат требует проведения повторного анализа. После чего проводят ультразвуковое исследование и анализируют кровоток;
- 4 и меньше – патологическое состояние, при котором требуется постоянное наблюдение и проведение лечения.
Чтобы успешно провести КТГ плода, а расшифровка произошла максимально точно, следует правильно подготовиться к анализу.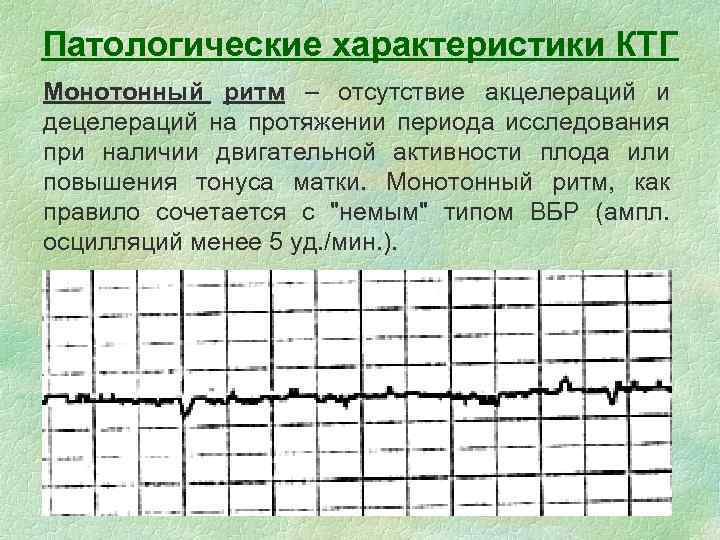
Для более эффективного сравнения полученных результатов с нормой КТГ при беременности, перед процедурой не будет лишним прогуляться на свежем воздухе. При исследовании длительное время придется находиться в неподвижном состоянии. В некоторых случаях анализ показывает не те баллы, расшифровка КТГ в этом случае произошла правильно, но были внешние факторы, которые повлияли на результат. В их число входят стресс и психоэмоциональное перенапряжение.
Кардиография – это исследование, информативность и точность которого напрямую зависит от квалификации специалиста. Врач точно должен знать, как выглядят схватки на КТГ, уметь распознать признаки патологии и отличать нормальные показатели от нарушений.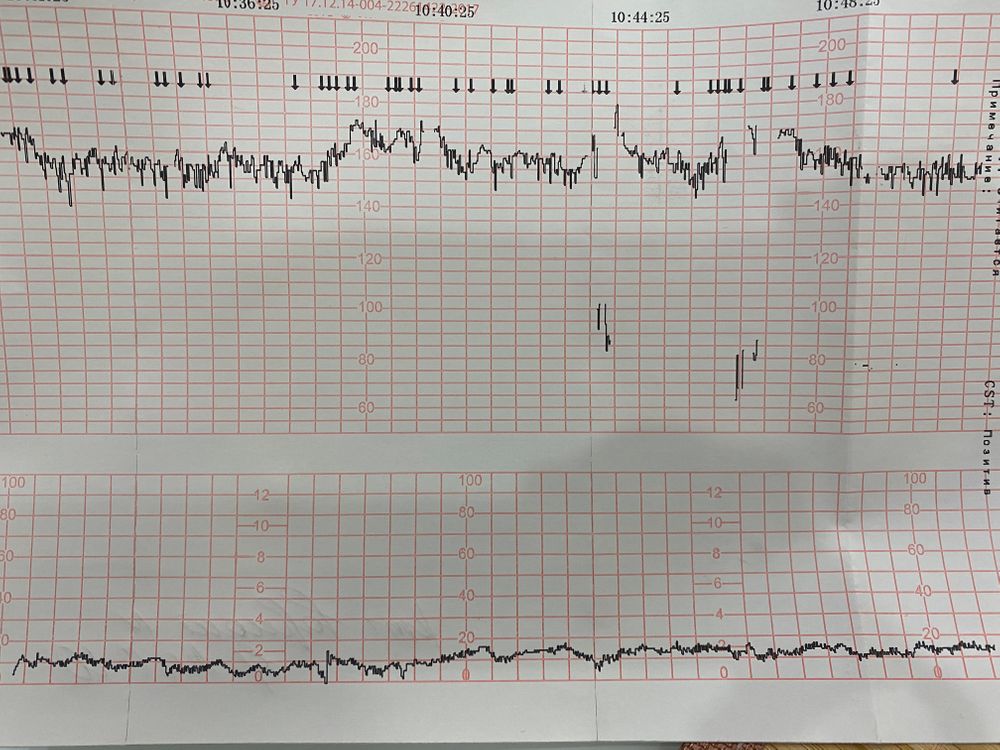
Поэтому так важно выбрать медицинское учреждение для проведения кардиографии, одной из лучших в Москве является «Латум клиника». Посетить клинику можно в г. Москва, Коровинское шоссе, д. 13, корп. 2.
Beam Search Decoding в обученных CTC нейронных сетях | by Harald Scheidl
Быстрый и хорошо работающий алгоритм со встроенной языковой моделью для декодирования вывода нейронной сети в контексте распознавания текста 0006 10 июл, 2018
Нейронные сети (NN), состоящие из сверточных слоев NN и рекуррентных слоев NN в сочетании с уровнем конечной коннекционистской временной классификации (CTC), являются хорошим выбором для распознавания (рукописного) текста.
Результатом НС является матрица, содержащая вероятности символов для каждого временного шага (положение по горизонтали), пример показан на рис. 1. Эта матрица должна быть декодирована, чтобы получить окончательный текст. Одним из алгоритмов для достижения этого является декодирование поиска луча, которое может легко интегрировать языковую модель на уровне символов.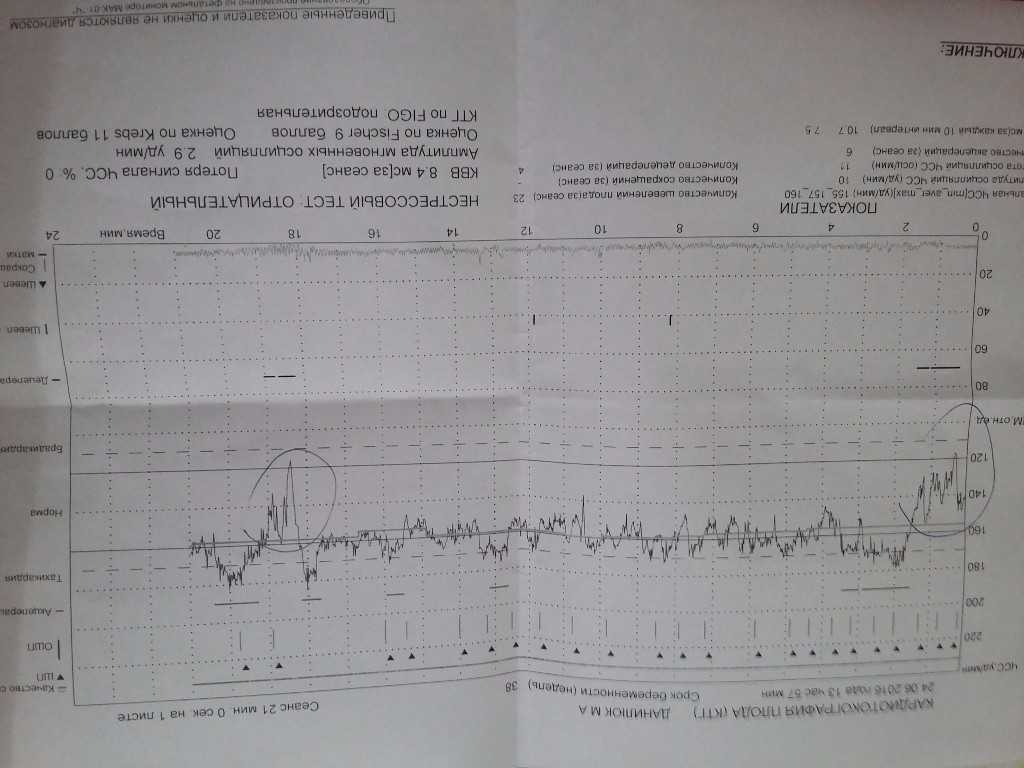
Мы начнем обсуждение с краткого обзора CTC и лучшего декодирования пути. Затем мы обсудим строительные блоки (базовый алгоритм, оценка CTC, языковая модель) алгоритма декодирования поиска луча CTC. Наконец, я укажу вам на реализацию Python, которую вы можете использовать для проведения собственных тестов и экспериментов.
Чтение статьи «Интуитивное объяснение временной классификации коннекционистов» поможет вам понять следующее обсуждение. Здесь я дам краткий обзор.
CTC позволяет обучать системы распознавания текста с помощью пар изображений и наземных текстов. Текст кодируется в выходной матрице NN путями, которые содержат один символ за временной шаг, например. «ab» или «aa» — возможные пути на рис. 1. Я покажу текст в двойных кавычках «текст», а пути в одинарных кавычках «путь».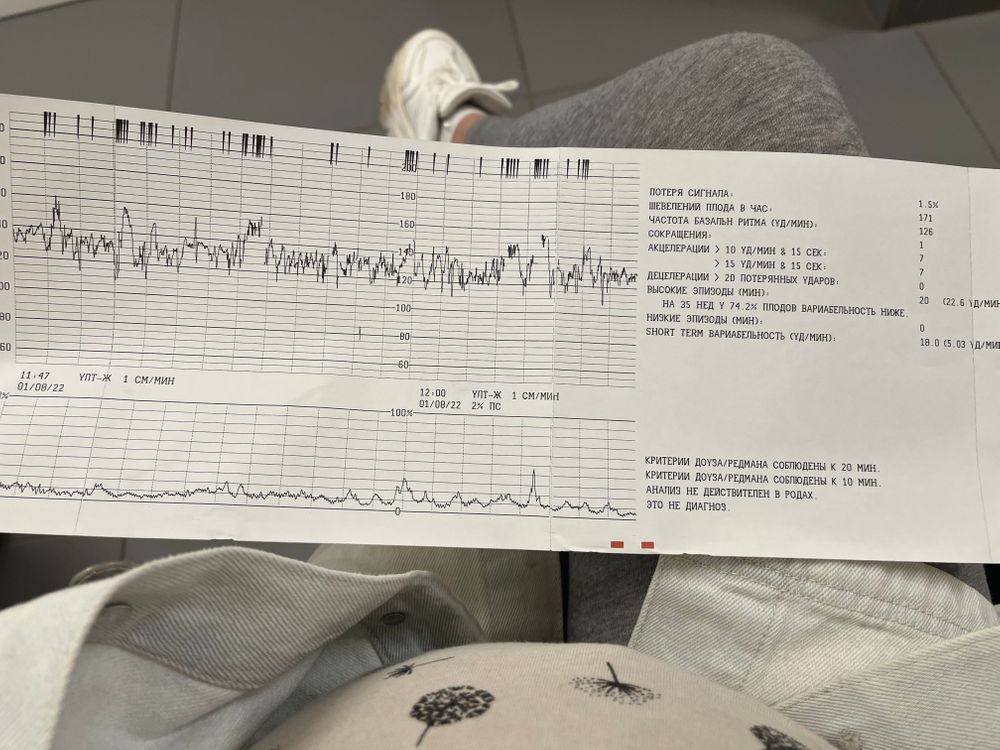
Путь кодирует текст следующим образом: каждый символ текста может повторяться произвольное количество раз. Кроме того, между символами может быть вставлено произвольное количество пробелов CTC (несимвольных, не путать с пробельным символом, обозначаемым в этой статье как «-»). В случае повторяющихся символов (например, «пицца») между этими повторяющимися символами в пути должен быть хотя бы один пробел (например, «пицца»).
Вот примеры текстов с соответствующими путями:
- «to» → ‘-t-o—‘, ‘tttttttt-ooo-‘, ‘to’, …
- «hello» → ‘h-ellllll-ll -ооо’, ‘привет-ло’, …
- «а» → ‘аа’, ‘а-‘, ‘-а’, …
Как видите, может быть более одного пути, соответствующего тексту . Когда нас интересует вероятность текста, мы должны просуммировать вероятности всех соответствующих путей. Вероятность одного пути является произведением вероятностей символов на этом пути, например. для пути «аа» на рис. 1 это 0,2·0,4=0,08.
Декодирование наилучшего пути — простейший метод декодирования выходной матрицы:
- Объедините наиболее вероятные символы на временной шаг, чтобы получить наилучший путь.

- Затем отмените кодировку, сначала удалив повторяющиеся символы, а затем удалив все пробелы. Это дает нам распознанный текст.
Давайте рассмотрим пример: матрица показана на рис. 2. Символ с наибольшим значением является пустым для обоих временных шагов t0 и t1. Итак, лучший путь — «—». Затем мы отменяем кодировку и получаем текст «». Далее, мы можем рассчитать вероятность пути, умножив вероятности символов, что в данном примере составляет 0,8·0,6=0,48.
Рис. 2: Объедините наиболее вероятные символы на временной шаг, чтобы получить наилучший путь.Декодирование лучшего пути выполняется быстро, нам нужно только найти символ с наибольшим количеством очков для каждого временного шага. Если у нас есть C символов и T временных шагов, алгоритм имеет время работы O (T·C).
Лучшее декодирование пути быстрое и простое, что, конечно же, является хорошим свойством. Но он может не работать в определенных ситуациях, подобных показанной на рис. 2. На рис. 3 показаны все пути, соответствующие тексту «а»: «аа», «а-» и «-а».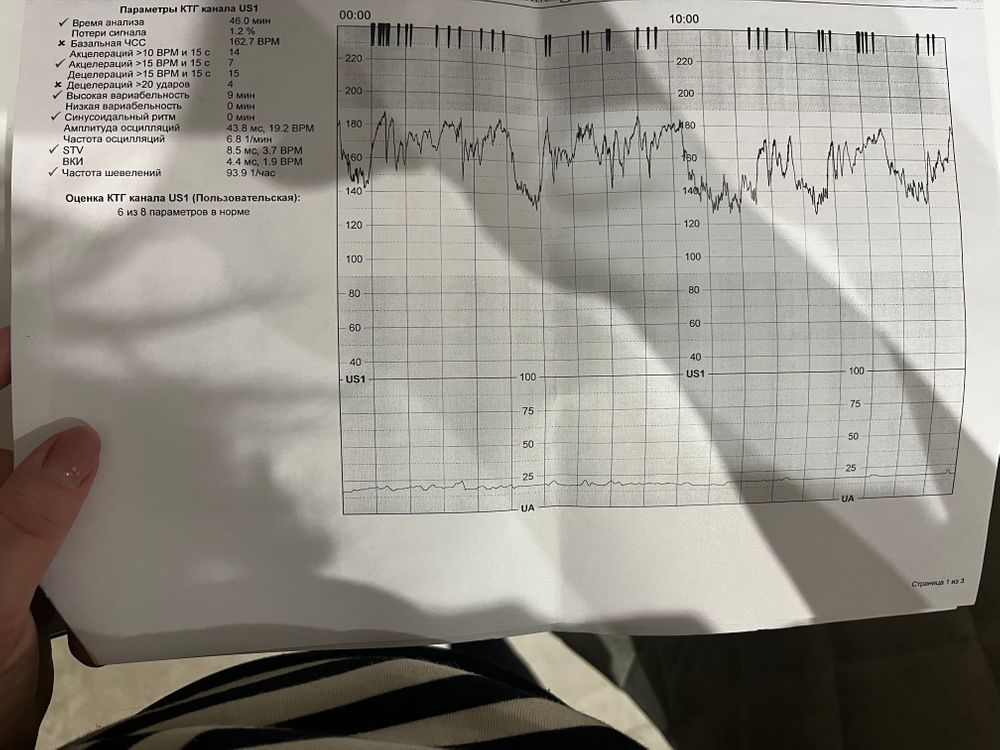 Вероятность текста «а» равна сумме всех вероятностей указанных путей: 0,2·0,4+0,2·0,6+0,8·0,4=0,52. Итак, «а» более вероятно, чем «» (0,52>0,48). Нам нужен лучший алгоритм, чем лучшее декодирование пути, который может справиться с такими ситуациями.
Вероятность текста «а» равна сумме всех вероятностей указанных путей: 0,2·0,4+0,2·0,6+0,8·0,4=0,52. Итак, «а» более вероятно, чем «» (0,52>0,48). Нам нужен лучший алгоритм, чем лучшее декодирование пути, который может справиться с такими ситуациями.
Декодирование поиска луча итеративно создает текстовые кандидаты (лучи) и оценивает их. Псевдокод для базовой версии показан на рис. 4.: список лучей инициализируется пустым лучом (строка 1) и соответствующей оценкой (2). Затем алгоритм выполняет итерацию по всем временным шагам выходной матрицы NN (3–15). На каждом временном шаге сохраняются только лучшие лучи с предыдущего временного шага (4). Ширина луча (BW) определяет количество сохраняемых лучей. Для каждого из этих лучей вычисляется оценка на текущем временном шаге (8). Далее каждый луч дополняется всеми возможными символами из алфавита (10) и снова подсчитывается балл (11). После последнего временного шага в результате возвращается лучший луч (16).
Давайте представим, как алгоритм декодирует наш пример вывода NN с BW 2 и алфавитом {«a», «b»}. На рис. 5 показаны как декодируемый выход NN, так и дерево лучей. Алгоритм начинается с пустого луча «», который соответствует корневому узлу дерева. Затем луч копируется и расширяется всеми возможными символами алфавита. Это дает нам лучи «а», «б» и «». Позже мы подробнее рассмотрим, как рассчитать балочные баллы. А пока воспользуемся своей интуицией и увидим, что каждому лучу соответствует только один путь: «а» с вероятностью 0,2, «б» с вероятностью 0 и «-» с вероятностью 0,8.
На следующей итерации мы просто сохраняем 2 лучших луча (по BW) с предыдущего временного шага, т.е. отбрасываем луч «b». Затем снова и копируем, и удлиняем оставшиеся лучи и получаем «аа», «аб», «а», «а», «б», «». Если два луча равны, как в случае с «а», мы просто объединяем их: суммируем баллы и оставляем только один из лучей. Мы снова используем нашу интуицию для подсчета очков. Каждый луч, содержащий «b», имеет вероятность 0. «aa» также имеет вероятность 0, потому что для кодирования текста с повторяющимися символами мы должны поместить пробел между ними (например, «a-a»), что невозможно. для пути длины 2. Наконец, остаются лучи «а» и «». Мы уже рассчитали для них вероятности: 0,52 и 0,48.
Каждый луч, содержащий «b», имеет вероятность 0. «aa» также имеет вероятность 0, потому что для кодирования текста с повторяющимися символами мы должны поместить пробел между ними (например, «a-a»), что невозможно. для пути длины 2. Наконец, остаются лучи «а» и «». Мы уже рассчитали для них вероятности: 0,52 и 0,48.
Мы завершили последнюю итерацию, и последним шагом алгоритма является возврат луча с наивысшей оценкой, которая в этом примере равна «а».
Рис. 5: Выход NN и дерево лучей с алфавитом = {«a», «b»} и BW = 2. Мы еще не говорили о том, как подсчитывать лучи. Мы разделяем оценку луча на количество путей, оканчивающихся пробелом (например, «аа-»), и путей, заканчивающихся непробелом (например, «ааа»). Обозначим вероятность всех путей, заканчивающихся пробелом и соответствующих лучу b на временном шаге t, через Pb(b, t) и через Pnb(b, t) для непустого случая. Тогда вероятность Ptot(b, t) луча b на временном шаге t является просто суммой Pb и Pnb, т. е. Ptot(b, t)=Pb(b, t)+Pnb(b, t).
На рис. 6 показано, что происходит, когда мы расширяем путь. Есть три основных случая: расширение пробелом, расширение повторением последнего символа и расширение каким-либо другим символом. Когда мы сворачиваем расширенные пути, мы либо получаем неизмененный (скопированный) луч («a» → «a»), либо получаем расширенный луч («a» → «aa» или «ab»). Мы можем использовать эту информацию и в обратном направлении: если мы удлиняем луч, мы знаем, какие пути мы должны учитывать для подсчета очков.
Рис. 6: Эффект добавления символа к путям, оканчивающимся пробелом и непустым.Давайте посмотрим, как итеративно вычислить Pb и Pnb. Обратите внимание, что мы всегда добавляем, а не присваиваем вычисляемые значения (+= вместо =), это неявно реализует слияние лучей, обсуждавшееся ранее. Все значения Pb и Pnb изначально установлены равными 0.
Копировать луч
Чтобы скопировать луч, мы можем расширить соответствующие пути пробелом и получить пути, заканчивающиеся пробелом: Pb(b, t)+=Ptot(b, t-1)·mat(пусто, t).
Далее, мы можем расширить пути, заканчивающиеся непробелом, на последний символ (если луч непуст): Pnb(b, t)+=Pnb(b, t-1)·mat(b[- 1], t), где -1 индексирует последний символ в луче.
Расширить луч
Есть два случая. Либо мы продлеваем луч на символ с, отличный от последнего символа, тогда в путях нет необходимости разделять пробелы: Pnb(b+c, t)+=Ptot(b, t-1)·mat(c, т).
Или последний символ b[-1] повторяется, тогда мы должны убедиться, что пути заканчиваются пробелом: Pnb(b+c, t)+=Pb(b, t-1)·mat(c, t ).
Нам не нужно заботиться о Pb(b+c, t), потому что мы добавили непустой символ.
Модель языка на уровне символов (LM) оценивает последовательность символов. Мы ограничиваем наш LM для подсчета одиночных символов (униграмма LM) и пар символов (биграмма LM). Обозначим униграммную вероятность символа c как P(c) и биграммную вероятность символов c1, c2 как P(c2|c1). Оценка текста «привет» — это вероятность увидеть одиночное «h», а также вероятность увидеть рядом пару «h» и «e», а рядом — пару «e» и «l».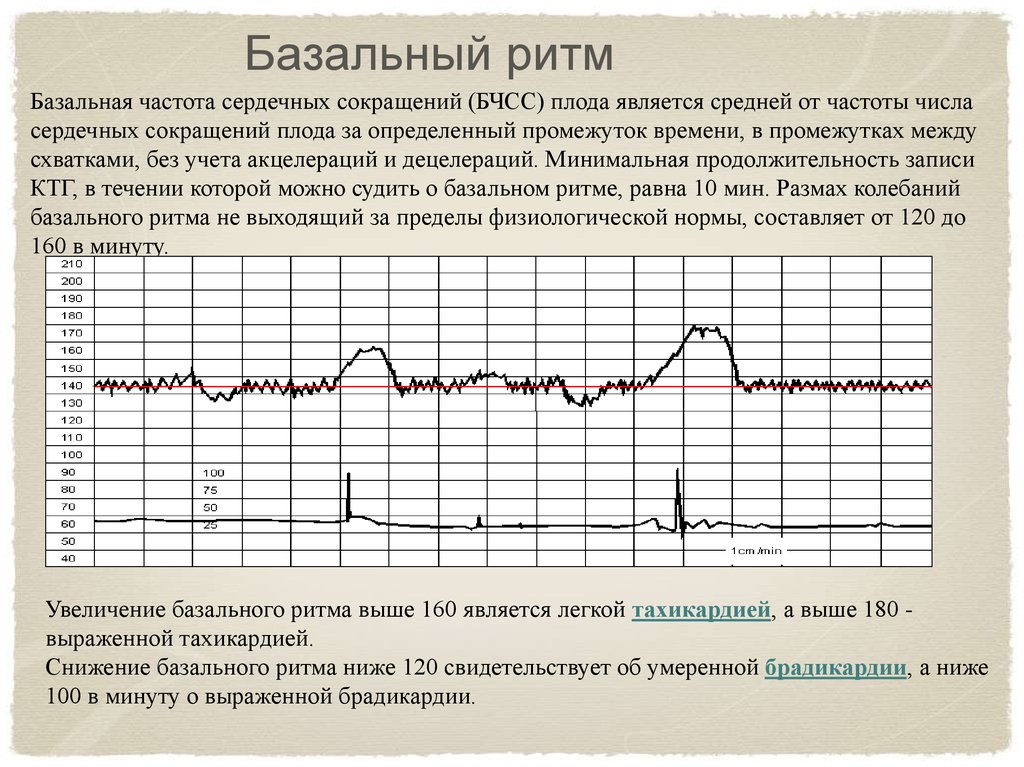 друг друга, …
друг друга, …
Вероятность последовательности символов c1, c2, c3, … равна: P(c1, c2, c3, …)=P(c1)·P(c2|c1)·P(c3|c2)·…
Обучить такой LM из большого текста несложно: мы просто считаем, как часто встречается символ, и делим на общее количество символов, чтобы получить вероятность униграммы. И мы считаем, как часто встречается пара символов, и нормализуем ее, чтобы получить вероятность биграммы.
Алгоритм поиска луча CTC показан на рис. 7. Он похож на уже показанную базовую версию, но включает код для оценки лучей: скопированные лучи (строки 7–10) и расширенные лучи оцениваются (15–19).). Далее LM применяется при удлинении луча b на символ c (строка 14). В случае односимвольного луча мы применяем оценку униграммы P(c), а для более длинных лучей мы применяем оценку биграммы P(b[-1], c). Оценка LM для луча b помещается в переменную Ptxt(b). Когда алгоритм ищет лучи с лучшими оценками, он сортирует их в соответствии с Ptot·Ptxt (строка 4), а затем выбирает лучшие BW.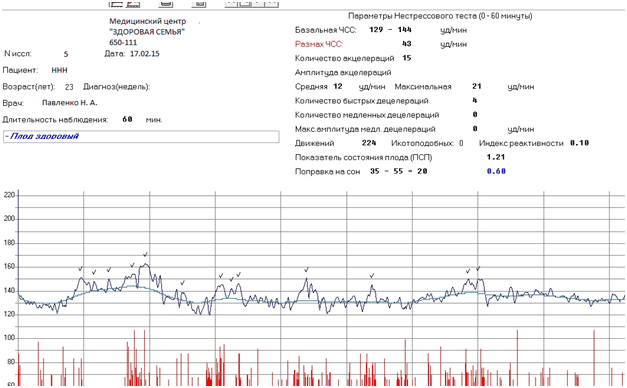
Время выполнения может быть получено из псевдокода: самый внешний цикл имеет T итераций. На каждой итерации сортируются N лучей, что составляет N·log(N). Выбираются лучшие лучи BW, и каждый из них расширяется на C символов. Следовательно, у нас есть N=BW·C балок, а общее время работы составляет O(T·BW·C·log(BW·C)).
Реализация декодирования с поиском луча (и других алгоритмов декодирования) на Python можно найти в репозитории CTCDecoder: соответствующий код находится в src/BeamSearch.py и src/LanguageModel.py. TensorFlow предоставляет операцию ctc_beam_search_decoder, однако не включает LM.
Декодирование NN в наборе данных IAM дает коэффициент ошибок символов 5,60 % при декодировании наилучшего пути и 5,35 % при декодировании с поиском луча. Время работы увеличивается с 12 мс до 56 мс на образец.
Вот образец из набора данных IAM (см. рис. 8), чтобы лучше понять, как поиск луча улучшает результаты. Декодирование выполняется с наилучшим декодированием пути и поиском луча с LM и без него.
Декодирование выполняется с наилучшим декодированием пути и поиском луча с LM и без него.
Наземная истина: "фальшивый друг семьи, похожий на"Рис. 8: Образец из набора данных IAM.
Расшифровка лучшего пути: "фальшивый друг фомли хэ ц"
Лучевой поиск: "фальшивый друг фомкли хэ ц"
Лучевой поиск с LM : "фальшивый друг семьи, ложь"
Декодирование поиска луча CTC является простым и быстрым алгоритмом и превосходит лучшее декодирование пути. LM уровня персонажа можно легко интегрировать.
- Реализация декодеров на Python (лучший путь, поиск луча и т. д.)
- Сравнение декодеров
- Декодирование поиска луча по слову
- Введение в CTC Сети
- Грейвс и Джейтли — На пути к сквозному распознаванию речи с помощью рекуррентных нейронных сетей
Расшифровка сообщения | Национальный архив
В этом упражнении учащиеся декодируют фиктивное сообщение, используя простой код замены. Он поддерживает изучение Zimmermann Telegram.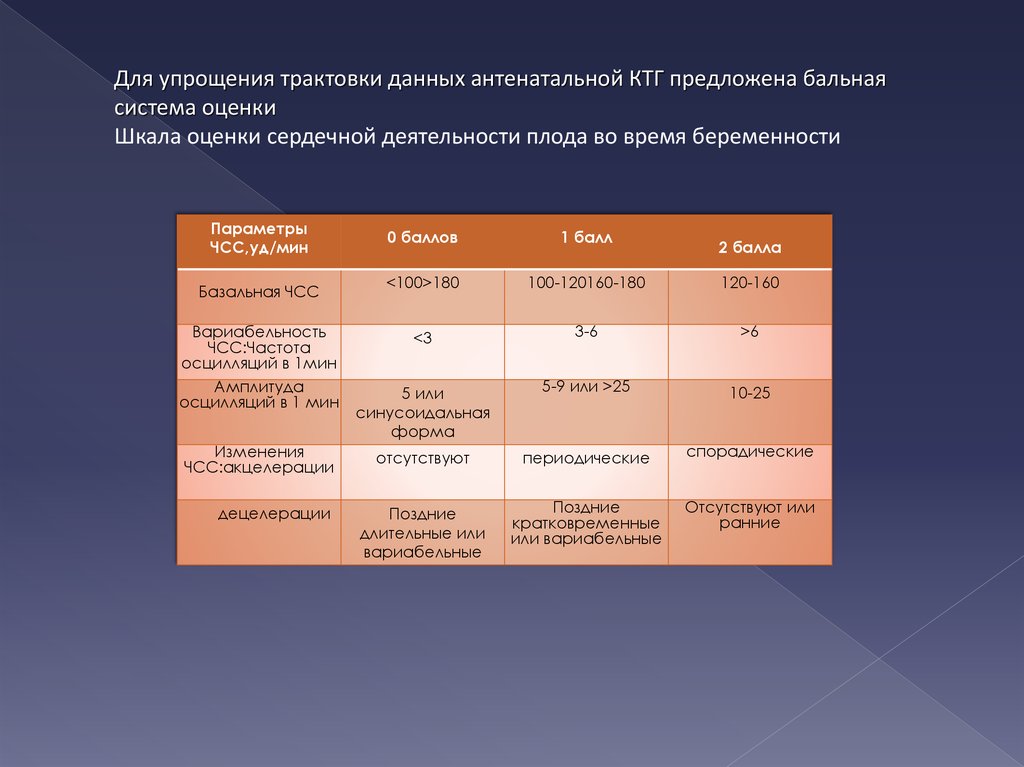 Чтобы расширить задание, попросите учащихся написать сообщение, используя код, а затем обменяться сообщениями для расшифровки.
Чтобы расширить задание, попросите учащихся написать сообщение, используя код, а затем обменяться сообщениями для расшифровки.
Поделитесь со студентами:
В кодах подстановки буквы открытого текста (сообщения, которое должно быть помещено в секретную форму) заменяются другими буквами, цифрами или символами. В этой кодовой системе каждая буква алфавита и каждая цифра от 1 до 9появляется в матрице сетки. Каждая буква в сетке заменяется двумя буквами в закодированном сообщении. Первая буква в сообщении идет от вертикальной оси сетки, а вторая буква — от ее горизонтальной оси. Например, если бы «DG» были первыми двумя буквами, которые нужно расшифровать в криптограмме, вы бы нашли букву «D» на вертикальной оси и букву «G» на горизонтальной оси. Проследите их через сетку до их пересечения в букве «А» в открытом тексте.
Чтобы расшифровать фиктивное сообщение в криптограмме, начните с группировки каждого набора из двух букв, начиная с первых двух букв (FG) и продолжая по всему сообщению. Кодовые буквы произвольно расположены группами по пять букв. Некоторые пары букв переносятся с одной строки на другую. Когда вы найдете каждую букву в сетке, вы должны написать эту букву над парой кодовых букв, которым она соответствует. В телеграмме нет знаков препинания, поэтому вашему учителю может понадобиться помощь в разъяснении сообщения.
Кодовые буквы произвольно расположены группами по пять букв. Некоторые пары букв переносятся с одной строки на другую. Когда вы найдете каждую букву в сетке, вы должны написать эту букву над парой кодовых букв, которым она соответствует. В телеграмме нет знаков препинания, поэтому вашему учителю может понадобиться помощь в разъяснении сообщения.
| Криптограмма | ||||||||
| ФГАФА | ААВХА | ДГАВС | ВАДАД | DVDDD | VGA | |||
| VXVDX | ДВДФ | AFDXG | XGDDG | АВФДВ | х | |||
| ВААФХ | GDADX | VDDXD | AVXXV | |||||
| АААВД | AVXDA | ВВГДД | САВДГ | DXGXV | СВДВФ | ВВАФД | КСАВАФ | |
| VXDXV | ДФДАФ | ХАВВВ | ФАВАФ | ВВВВВ | ADGXV | АКСАФД | GGXFX | АФАВВ |
| АДГДФ | VFAXV | ДВХХФ | ДАВКСГ | ДВААФ | XGDAD | СВДВФ | АВАФВ | ФДГАВ |
| ADVXV | ДАКСАФ | ДГСДА | ФАФВА | ААДГВ | ВВВХВ | ВДДФВ | ВГДВД | АВВСД |
| ФВДВХ | DADXA | Ф | ||||||
| ААААФА | ВДФВВ | ВХВДА | ВФГФГ | КСФДГВ | ВГДДА | DFFXV | ||
| XVDDF | ФДДС | |||||||
|
Сетка |
||||||
| А | D | F | G | В | Х | |
|
А |
В |
2 |
E |
5 |
р. 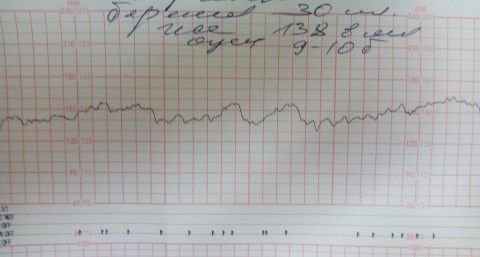
| |